/** * Sorts the specified array into ascending numerical order. * * <p>Implementation note: The sorting algorithm is a Dual-Pivot Quicksort * by Vladimir Yaroslavskiy, Jon Bentley, and Joshua Bloch. This algorithm * offers O(n log(n)) performance on many data sets that cause other * quicksorts to degrade to quadratic performance, and is typically * faster than traditional (one-pivot) Quicksort implementations. * * @param a the array to be sorted */ publicstaticvoidsort(int[] a){ DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); }
/* * Sorting methods for seven primitive types. */
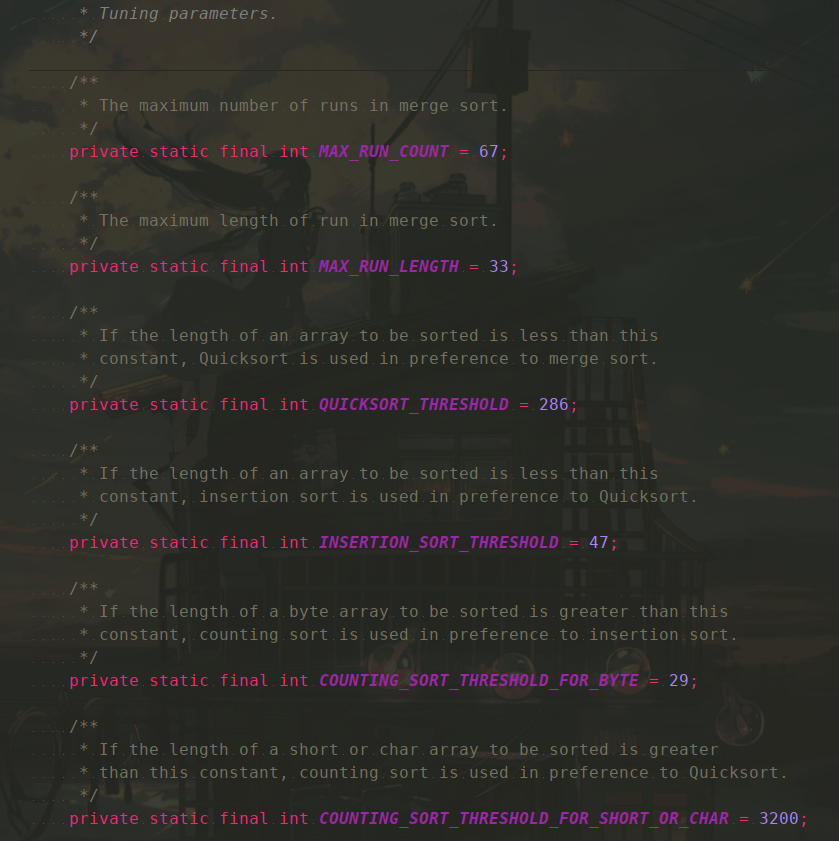
/** * Sorts the specified range of the array using the given * workspace array slice if possible for merging * * @param a the array to be sorted * @param left the index of the first element, inclusive, to be sorted * @param right the index of the last element, inclusive, to be sorted * @param work a workspace array (slice) * @param workBase origin of usable space in work array * @param workLen usable size of work array */ staticvoidsort(int[] a, int left, int right, int[] work, int workBase, int workLen){ // Use Quicksort on small arrays // 即, array.length < 286 时使用快排序 if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; }
/* * Index run[i] is the start of i-th run * run[i] 表示第 i-th 次运行 * (ascending or descending sequence). */ int[] run = newint[MAX_RUN_COUNT + 1]; int count = 0; run[0] = left;
// Check if the array is nearly sorted // 判断数组是否已经基本排好序(部分有序) for (int k = left; k < right; run[count] = k) { if (a[k] < a[k + 1]) { // ascending // while 循环结束后,k会指向连续生序元素的最后一个 while (++k <= right && a[k - 1] <= a[k]); } elseif (a[k] > a[k + 1]) { // descending // 同上, 类似地,k 会指向连续降序元素的最后一个 while (++k <= right && a[k - 1] >= a[k]); // 对这一部分进行翻转(reverse), 使其生序 for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) { int t = a[lo]; a[lo] = a[hi]; a[hi] = t; } } else { // equal for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) { // 数组中连续重复元素超过MAX_RUN_LENGTH(33)时 // 使用快排序 if (--m == 0) { sort(a, left, right, true); return; } } }
/* * The array is not highly structured, * use Quicksort instead of merge sort. * 如果数组非高度结构化,使用快排序 */ if (++count == MAX_RUN_COUNT) { sort(a, left, right, true); return; } }
// Check special cases // Implementation note: variable "right" is increased by 1. if (run[count] == right++) { // The last run contains one element run[++count] = right; } elseif (count == 1) { // The array is already sorted return; }
// Determine alternation base for merge byte odd = 0; for (int n = 1; (n <<= 1) < count; odd ^= 1);
// Use or create temporary array b for merging int[] b; // temp array; alternates with a int ao, bo; // array offsets from 'left' int blen = right - left; // space needed for b if (work == null || workLen < blen || workBase + blen > work.length) { work = newint[blen]; workBase = 0; } if (odd == 0) { System.arraycopy(a, left, work, workBase, blen); b = a; bo = 0; a = work; ao = workBase - left; } else { b = work; ao = 0; bo = workBase - left; }
// Merging for (int last; count > 1; count = last) { for (int k = (last = 0) + 2; k <= count; k += 2) { int hi = run[k], mi = run[k - 1]; for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) { if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) { b[i + bo] = a[p++ + ao]; } else { b[i + bo] = a[q++ + ao]; } } run[++last] = hi; } if ((count & 1) != 0) { for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao] ); run[++last] = right; } int[] t = a; a = b; b = t; int o = ao; ao = bo; bo = o; } }
其他相关的更详细内容可以自行移步到 JDK 源代码文档中查看。
Problem
本文只讨论简单的最原始的快排序(单基准, single-pivot )实现(伪代码如下), 即
1 2 3 4
QuickSort (if low < high): pi = partition(arr, low, high); QuickSort(arr, low, pi - 1); QuickSort(arr, pi + 1, high);
publicstaticvoidquickSort(int[] arr, int low, int high){ if (low < high) { /* pi is the partiioning index */ int pi = partition(arr, low, high); // Separately sort elements before // partition and after partition quickSort(arr, low, pi - 1); quickSort(arr, pi + 1, high); } }
publicstaticvoidquickSort(int[] arr, int low, int high){ while (low < high) { // pi is partitioning index int pi = partition(arr, low, high); // Separately sort elements before // partition and after partition quickSort(arr, low, pi - 1); low = pi + 1; } }
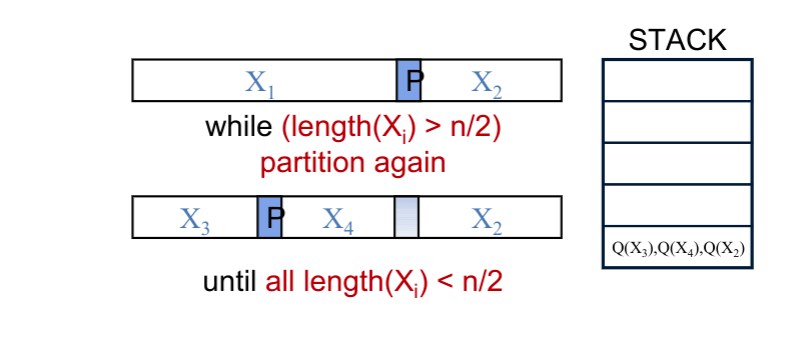
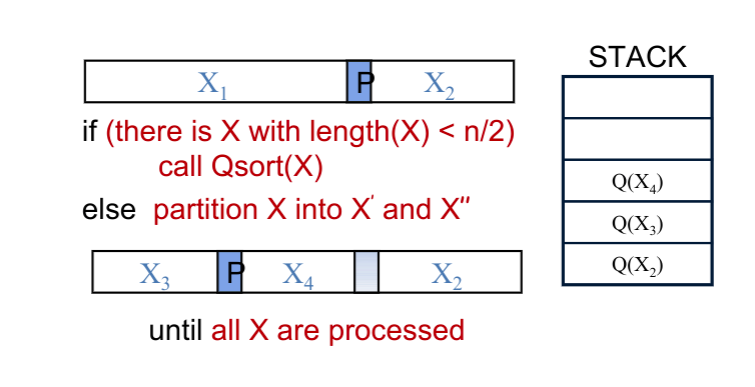
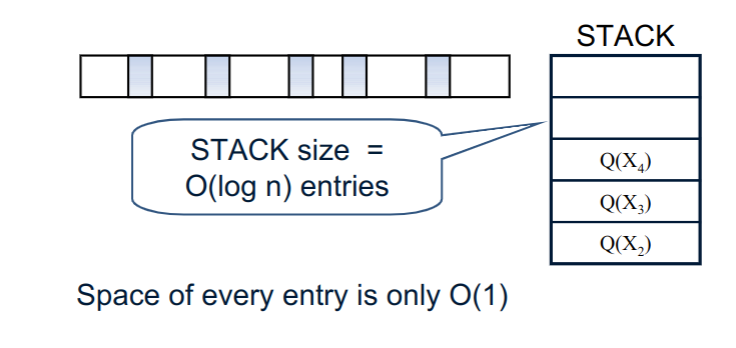
// java implementation publicclassQuick{ pulbic staticvoidsort(int[] arr){ quickSort(arr, 0, arr.length - 1); assertisSorted(arr); } /* This QuickSort requires O(log n) auxiliary space in worst case. */ privatestaticvoidquickSort(int[] arr, int low, int high){ while (low < high) { // pi is partitioning index int pi = partition(arr, low, high); // if left part is smaller, then recur for left // part and handle right part iteratively if (pi - low < high - pi) { quickSort(arr, low, pi - 1); low = pi + 1; } else { // else recur for right part quickSort(arr, pi+1, high); high = pi - 1; } } } privatestaticintpartition(int[] arr, int low, int high){ if (low > high) thrownew Exception("invalid arguments"); int i = low, j = high + 1; int povit = arr[low]; while (true) { while (arr[++i] < povit) if (i == high) break; while (arr[--j] > povit) if (j == low) break; // reduntant if (i > j) break; swap(arr, i, j); } if (j > low) swap(arr, low, j); return j; } ////////////// Help functions ////////////////////// privatestaticvoidswap(int[] arr, int i, int j){ int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } privatebooleanisSorted(int[] arr){ for (int i = 0; i < arr.length-1; i++) { if (arr[i] > arr[i+1]) returnfalse; } returntrue; } //////////////////////////////////////////////////////// }