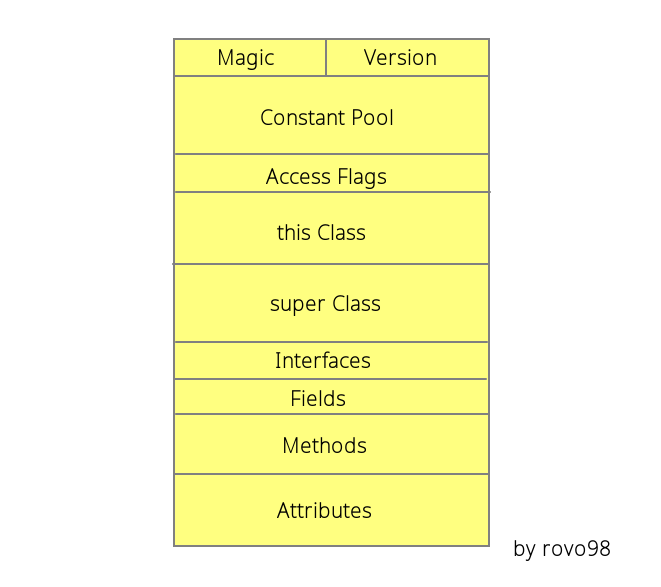
ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }
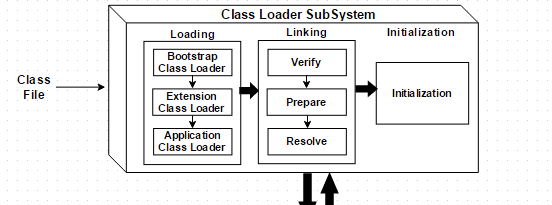
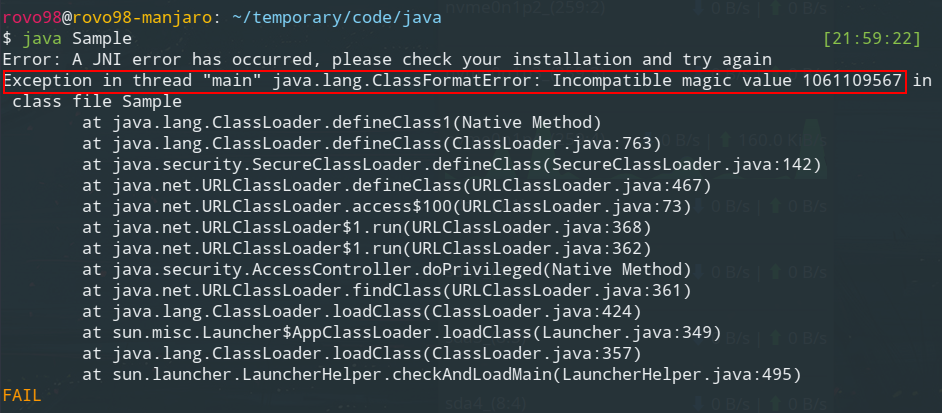
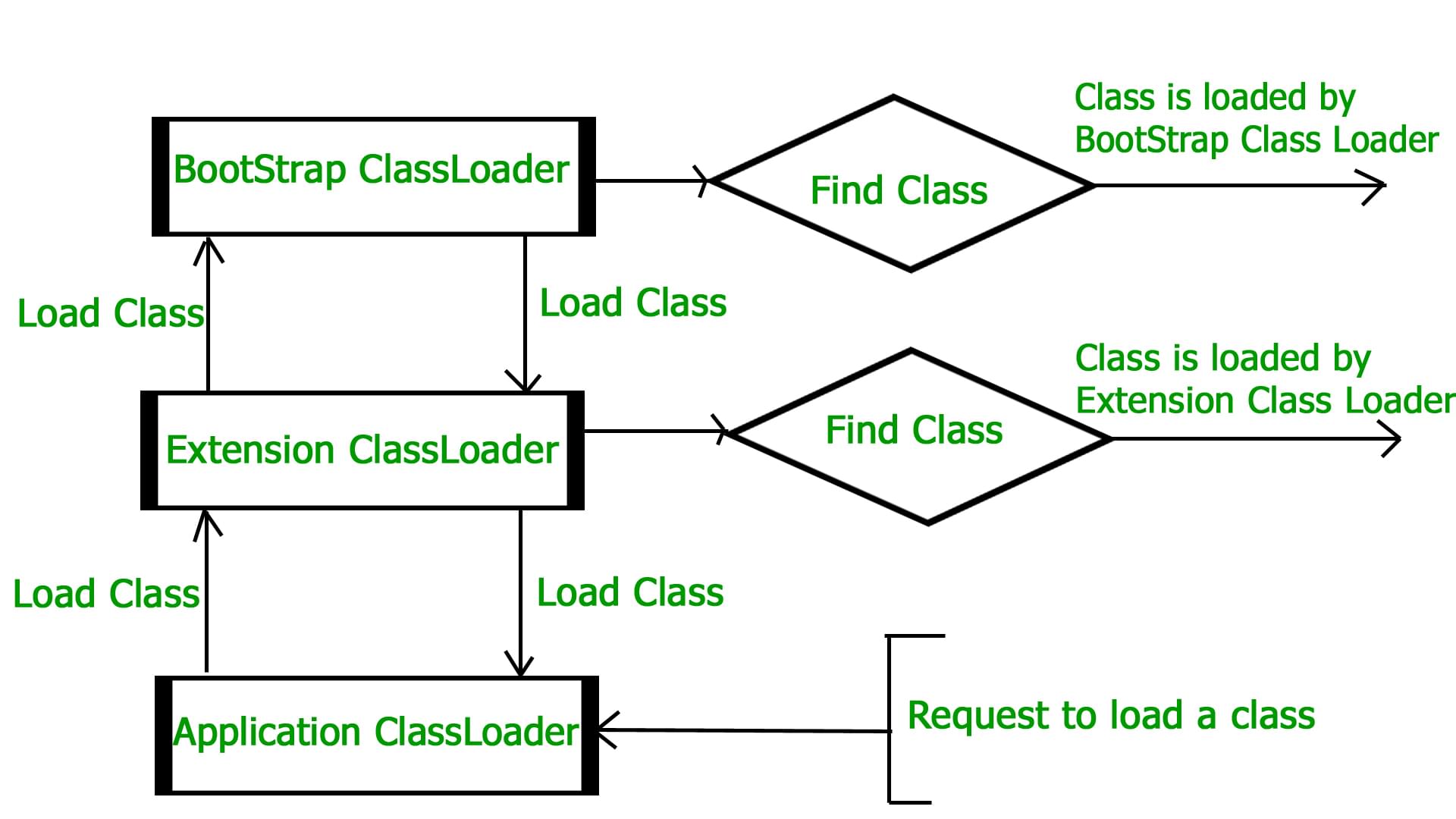
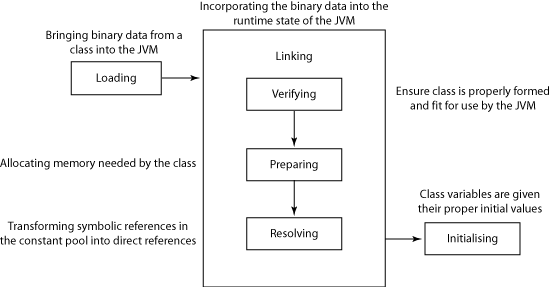
JVM在执行类的入口之前,首先必须找到类文件,然后将类文件装入JVM实例中,也就是JVM进程维护的内存区域(Runtime Data Area或Memory Area)中。我们都知道有一个叫做**类加载器(ClassLoader)**的工具负责把类加载到JVM实例中,抛开细节从操作系统层面观察,那么就是JVM实例在运行过程中通过IO从硬盘或者网络读取.class类文件,然后在JVM管辖的内存区域存放对应的文件。
/** * Loads the class with the specified <a href="#name">binary name</a>. The * default implementation of this method searches for classes in the * following order: * * <ol> * * <li><p> Invoke {@link #findLoadedClass(String)} to check if the class * has already been loaded. </p></li> * * <li><p> Invoke the {@link #loadClass(String) <tt>loadClass</tt>} method * on the parent class loader. If the parent is <tt>null</tt> the class * loader built-in to the virtual machine is used, instead. </p></li> * * <li><p> Invoke the {@link #findClass(String)} method to find the * class. </p></li> * * </ol> * * <p> If the class was found using the above steps, and the * <tt>resolve</tt> flag is true, this method will then invoke the {@link * #resolveClass(Class)} method on the resulting <tt>Class</tt> object. * * <p> Subclasses of <tt>ClassLoader</tt> are encouraged to override {@link * #findClass(String)}, rather than this method. </p> * * <p> Unless overridden, this method synchronizes on the result of * {@link #getClassLoadingLock <tt>getClassLoadingLock</tt>} method * during the entire class loading process. * * @param name * The <a href="#name">binary name</a> of the class * * @param resolve * If <tt>true</tt> then resolve the class * * @return The resulting <tt>Class</tt> object * * @throws ClassNotFoundException * If the class could not be found */ protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded // 先判断类是否已经加载 Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { // 判断顶层parent类加载器是否为null, 不为空使用它进行加载 if (parent != null) { c = parent.loadClass(name, false); } else { // parent 为 null, 使用系统内置类加载器 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader }
if (c == null) { // If still not found, then invoke findClass in order // to find the class. // 仍找不到,执行findClass方法继续查找 long t1 = System.nanoTime(); c = findClass(name);
// this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { // 找到类,进行解析 resolveClass(c); } // 返回类类型对象 return c; } }
/** * A demo class to be loaded to test the {@code UserDefinedClassLoader} */ publicstaticclassDemo{ publicstaticint example = 0; }
/** * UserDefined class loader. */ publicstaticclassUserDefinedClassLoaderextendsClassLoader{ private String classPath;
/** * default constructor * @param classPath the class path of the specify class to be loaded. */ publicUserDefinedClassLoader(String classPath){ this.classPath = classPath; }
@Override public Class<?> loadClass(String name) throws ClassNotFoundException { if (!name.contains("java.lang")) { // 排除加载系统的核心类 byte[] data = newbyte[0]; try { data = loadByte(name); } catch (Exception e) { e.printStackTrace(); } return defineClass(name, data, 0, data.length); } else { returnsuper.loadClass(name); } }
/** * Loading binary class file into the memory * @param name the name of the class file to be loaded. * @return binary data of the class file to be loaded. */ @SuppressWarnings("ResultOfMethodCallIgnored") privatebyte[] loadByte(String name) throws Exception { name = name.replaceAll("\\.", "/"); String dir = classPath + "/" + name + ".class"; FileInputStream fileInputStream = new FileInputStream(dir); int len = fileInputStream.available(); byte[] data = newbyte[len]; fileInputStream.read(data); fileInputStream.close(); return data; }
Visibility principle allows child class loader to see all the classes loaded by parent ClassLoader, but parent class loader can not see classes loaded by child.
/** * @author rovo98 * date: 2019.04.08 22:36 */ publicclassVisibilityPrincipleTest{ /** * Driver the program to test the visibility principle in class loading. * * @param args command-line arguments. */ publicstaticvoidmain(String[] args){ try { ClassLoader classLoader = VisibilityPrincipleTest.class.getClassLoader(); // print out the class loader of this class. System.out.println("VisibilityPrincipleTest's class loader is " + classLoader); ClassLoader parentClassLoader = classLoader.getParent();
// loading this class using its parent class loader Class.forName("com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest", true, parentClassLoader); } catch (ClassNotFoundException e) { e.printStackTrace(); Logger.getLogger(VisibilityPrincipleTest.class.getName()).log(Level.SEVERE, null, e); } } }
VisibilityPrincipleTest's class loader is sun.misc.Launcher$AppClassLoader@18b4aac2 java.lang.ClassNotFoundException: com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest.main(VisibilityPrincipleTest.java:24) Apr 08, 2019 10:42:41 PM com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest main SEVERE: null java.lang.ClassNotFoundException: com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at com.rovo98.miscExamples.classLoading.VisibilityPrincipleTest.main(VisibilityPrincipleTest.java:24)
Process finished with exit code 0
uniqueness principle
Uniqueness principle allows to load a class exactly once, which i sbasically achieved by delegation and ensures that child ClassLoader doesn’t reload the class already loaded by parent.
Exception in thread "main" java.lang.ClassCastException: basical.test.DifferentClassLoaderTest cannot be cast to basical.test.DifferentClassLoaderTest at basical.test.DifferentClassLoaderTest.main(DifferentClassLoaderTest.java:40)
/** * @author rovo98 * date: 2019.04.09 15:01 */ publicclassClassReloading{ /** * Driver the program to test the class reloading * * @param args command-line arguments. */ @SuppressWarnings("InfiniteLoopStatement") publicstaticvoidmain(String[] args)throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InterruptedException, InstantiationException {
int count = 0; for (;;) { count++; // Using infinite loop to make the thread keep running. String className = "com.rovo98.miscExamples.hotDeployment.ClassReloading$User"; Class<?> target = new MyClassLoader().loadClass(className); // Invokes the method of the loaded class using Reflection System.out.println(count + " round: loading target successfully, ready to invoke the method!"); target.getDeclaredMethod("execute").invoke(target.newInstance());
// If we use system class loader, it will be 'AppClassLoader'
// Sleep to avoid the case happen that it will occurs 'ClassNotFoundException' error // if the target class had been removed. // so make the thread stop to avoid this case happen. Thread.sleep(10000);
}
}
/** * The class to be tested for loading. */ publicstaticclassUser{ publicvoidexecute(){ ask(); // say(); } voidask(){ System.out.println("What is your name?"); } voidsay(){ System.out.println("My name is rovo98!"); }
} // a user defined classloader publicstaticclassMyClassLoaderextendsClassLoader{ @SuppressWarnings("ResultOfMethodCallIgnored") @Override public Class<?> loadClass(String name) throws ClassNotFoundException { String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class"; InputStream stream = getClass().getResourceAsStream(fileName); if (stream == null) { returnsuper.loadClass(name); // load the class using system default class loaders } try { byte[] b = newbyte[stream.available()]; // write the stream into the byte array b stream.read(b); return defineClass(name, b, 0, b.length); } catch (IOException e) { e.printStackTrace(); }
1 round: loading target successfully, ready to invoke the method! What is your name? 2 round: loading target successfully, ready to invoke the method! What is your name? 3 round: loading target successfully, ready to invoke the method! My name is rovo98! 4 round: loading target successfully, ready to invoke the method! What is your name? 5 round: loading target successfully, ready to invoke the method! What is your name? 6 round: loading target successfully, ready to invoke the method! My name is rovo98! 7 round: loading target successfully, ready to invoke the method! My name is rovo98! ... ...
/** * @author rovo98 * date: 2019.04.09 16:18 */ publicclassContextReloading{ /** * Driver the program to test the {@code ContextReloading}. * * @param args command-line arguments. */ @SuppressWarnings("InfiniteLoopStatement") publicstaticvoidmain(String[] args)throws ClassNotFoundException, NoSuchMethodException, InstantiationException, IllegalAccessException, InvocationTargetException, InterruptedException {
int count = 0; for (;;) { count++; Object context = newContext(); System.out.println(count + " round: context loaded successfully, ready to invoke the methods!"); invokeContext(context);
Thread.sleep(8000); } }
/** * 1. Create the Context * 2. Context object is used as a GC root * 3. Before returning the context object, we call the init() method. * * @return a Context Object. */ publicstatic Object newContext()throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException { String className = "com.rovo98.miscExamples.hotDeployment.ContextReloading$Context"; Class<?> contextClass = new MyClassLoader().loadClass(className); Object context = contextClass.newInstance(); contextClass.getDeclaredMethod("init").invoke(context);
return context; }
/* Simply invokes the method of the context class since the method's rules will be update during the runtime */ publicstaticvoidinvokeContext(Object context)throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { context.getClass().getDeclaredMethod("showUser").invoke(context); }
publicstaticclassContext{ private UserService userService = new UserService(); publicvoidshowUser(){ System.out.println(userService.getUserMessage()); System.out.println("method invoked"); } // initialize the object publicvoidinit(){ // System.out.println("init successfully"); UserDao userDao = new UserDao(); userDao.setUser(new User()); userService.setUserDao(userDao); } }
// simple user service object publicstaticclassUserService{ private UserDao userDao; public String getUserMessage(){ return userDao.getUserName(); } publicvoidsetUserDao(UserDao userDao){ this.userDao = userDao; } }
// simple user DAO object publicstaticclassUserDao{ private User user; public String getUserName(){ return user.getName(); // return user.getAlias(); } publicvoidsetUser(User user){ this.user = user; } }
// A simple model class publicstaticclassUser{ private String name = "rovo98"; private String alias = "testUser";
/** * Driver the program to test loading the same class using different classloader * @param args command-line arguments. */ publicstaticvoidmain(String[] args)throws ClassNotFoundException, NoSuchFieldException, IllegalAccessException, InstantiationException { Class<?> clazz1 = Cat.class; String className = "com.rovo98.miscExamples.classLoading.DifferentClassLoaders$Cat"; Class<?> clazz2 = new MyClassLoader().loadClass(className);
System.out.println("Compare their class name(seems to be the same): "); System.out.println("clazz1: " + clazz1.getName()); System.out.println("clazz2: " + clazz2.getName()); System.out.println();
System.out.println("Compare their class loader: "); System.out.println("clazz1's classloader: " + clazz1.getClassLoader()); System.out.println("clazz2's classloader: " + clazz2.getClassLoader()); System.out.println();
System.out.println("The static field value: " + Cat.age); Cat.age = 3; // change the static field of the class Cat System.out.println("And to see the difference: "); Field f1 = clazz1.getDeclaredField("age"); f1.setAccessible(true); Field f2 = clazz2.getDeclaredField("age"); f2.setAccessible(true); System.out.println("clazz1's static field: " + f1.getInt(clazz1.newInstance()) + "."); System.out.println("clazz2's static field: " + f2.getInt(clazz2.newInstance()) + ".");
}
/** * A simple for testing */ publicstaticclassCat{ privatestaticint age = 2; } publicstaticclassMyClassLoaderextendsClassLoader{ @SuppressWarnings("ResultOfMethodCallIgnored") @Override public Class<?> loadClass(String name) throws ClassNotFoundException { String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class"; InputStream is = getClass().getResourceAsStream(fileName); if (is == null) { returnsuper.loadClass(name); // loading the class using system default classloader if MyClassLoader // can not the specify class. } try { byte[] b = newbyte[is.available()]; is.read(b); return defineClass(name, b, 0, b.length);
Compare their class name(seems to be the same): clazz1: com.rovo98.miscExamples.classLoading.DifferentClassLoaders$Cat clazz2: com.rovo98.miscExamples.classLoading.DifferentClassLoaders$Cat
Compare their class loader: clazz1's classloader: sun.misc.Launcher$AppClassLoader@18b4aac2 clazz2's classloader: com.rovo98.miscExamples.classLoading.DifferentClassLoaders$MyClassLoader@7f31245a
The static field value: 2 And to see the difference: clazz1's static field: 3. clazz2's static field: 2.